
[bibshow file=ref.bib]
Nesse relatório apresento o método que propus no PIBIC e no TCC para realizar a estimação das formantes do trato vocal. Os que estavam presentes na minha apresentação do TCC sabem1 que um ponto questionado por Elyson foi o fato de que o texto não apresentava a estrutura do método proposto para a estimação e a diferença que ele causa no resultado. Assim, também me dedico aqui aos testes iniciais dos resultados de estimação do método. Esse método foi proposto para tentar resolver o problema na escolha da ordem de predição linear pra estimar as formantes.
Mas pera aí, o que são formantes mesmo?
Muito boa a sua pergunta! Antes de explicar o método para estimar as formantes, é válido explicar mais brevemente o que elas são (onde vivem, o que comem…). Revendo o processo de produção da voz, que já discutimos em algumas reuniões, temos que a vibração das cordas vocais modula o ar bombeado pelos pulmões gerando um sinal, denominado pulso glotal. Esse sinal é modificado na sua passagem pelas cavidades da região que vai das pregas vocais aos lábios, que é chamada de trato vocal, onde sofre ressonância.
Com isso, podemos dizer que as frequências formantes são as frequências em que o trato vocal provoca ressonâncias no sinal glotal. O que define as formantes é o posicionamento da estrutura óssea e muscular do trato vocal ao passo que as formantes determinam o som vocálico emitido. Elas são normalmente nomeadas em ordem crescente de frequência. Assim, a formante de frequência mais baixa é  (primeira formante), a segunda mais baixa é
(primeira formante), a segunda mais baixa é  (segunda formante) e por aí vai…
(segunda formante) e por aí vai…
Tá bom. Mas então como que faz pra estimar essas tais formantes?
Existem diversas maneiras de fazer isso mas, nesse relatório, o foco será dado em utilizar predição linear para que essas frequências sejam estimadas. Então, primeiramente, precisamos entender como funcionam os preditores lineares para prosseguirmos.
Predição Linear
A ideia por trás do preditor linear consiste na tentativa de “prever” a amostra de um sinal com base na combinação linear de um determinado número de amostras anteriores. Isso significa dizer que a previsão para a  -ésima amostra de um sinal
-ésima amostra de um sinal ![x[n]](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-7678456914fac638e67ac10b23409f76_l3.png "Rendered by QuickLaTeX.com") utilizando
utilizando  amostras anteriores é feita de acordo com a seguinte expressão:
amostras anteriores é feita de acordo com a seguinte expressão:
(1) ![\begin{equation*} \hat x[i] = \sum_{j=1}^k a_j x[i-j] \end{equation*}](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-01c2356a38522d4e58b31cc36cd30e4a_l3.png "Rendered by QuickLaTeX.com")
de forma que  são os coeficientes do preditor e o número de amostras utilizadas é nomeado como ordem do preditor. O erro da predição é obtido pela diferença entre as amostras
são os coeficientes do preditor e o número de amostras utilizadas é nomeado como ordem do preditor. O erro da predição é obtido pela diferença entre as amostras ![x[i]](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-420b9ada11438ab31292fbc69713bd2a_l3.png "Rendered by QuickLaTeX.com") e as amostras estimadas
e as amostras estimadas ![\hat x[i]](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-838094c1b74676bcccf926a61b9ec367_l3.png "Rendered by QuickLaTeX.com") . A tarefa que o preditor desempenha então é de minimizar o erro da predição para cada amostra, ajustando os coeficientes . Não entrarei nos detalhes nesse relatório, mas esse ajuste é realizado seguindo o método dos mínimos quadrados, utilizando pseudo-inversão.
. A tarefa que o preditor desempenha então é de minimizar o erro da predição para cada amostra, ajustando os coeficientes . Não entrarei nos detalhes nesse relatório, mas esse ajuste é realizado seguindo o método dos mínimos quadrados, utilizando pseudo-inversão.
Estimando Formantes por Predição Linear
O importante para estimar as formantes por predição linear é que, ao aplicar a transformada Z em (1), encontramos a seguinte função de transferência:
(2) 
cujo módulo permite a estimação do contorno espectral do sinal analisado, uma vez que os coeficiente já tenham sido encontrados. A partir do contorno espectral estimado (exemplificado na Figura 1) é possível estimar as formantes pela detecção de seus picos.
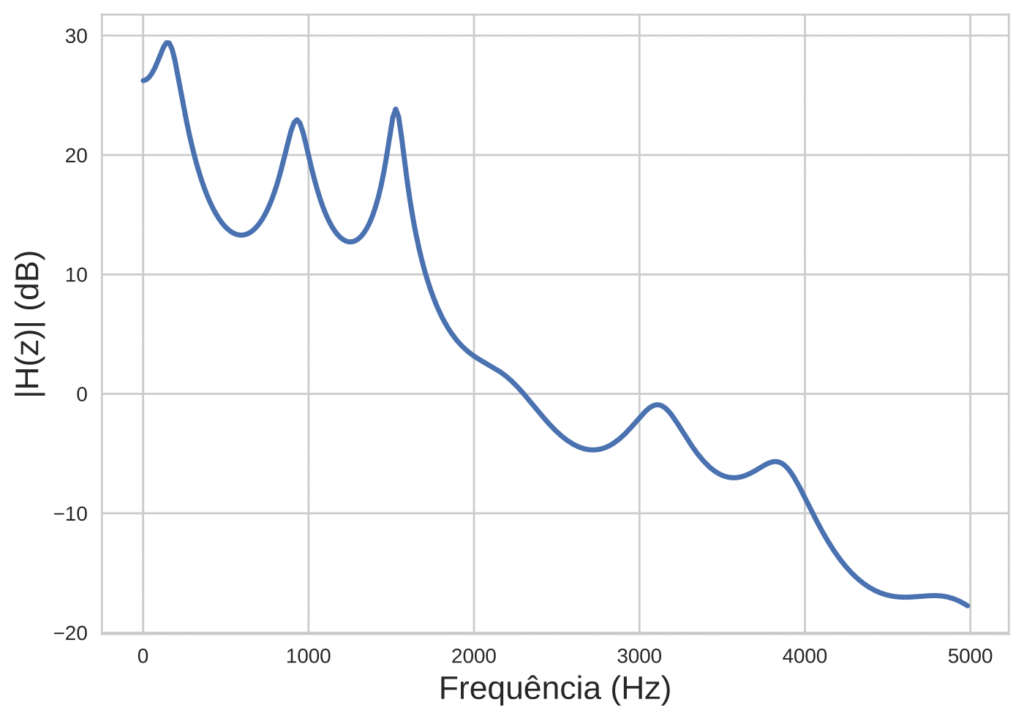
Até aqui, tudo tranquilo. Entretanto, existem alguns problemas para utilizar esse método na estimação de formantes. Um desses problemas consiste no fato de que o número de picos espectrais estimados varia de acordo com a ordem e o sinal analisado. Então, qual ordem que deve ser utilizada no preditor para uma melhor estimação? “Por acaso”, o método a ser apresentado propõe-se a resolver esse problema.
Avaliando os Resultados
Antes de explicar melhor o método proposto, vamos precisar de uma forma de avaliar o resultados da estimação de formantes. Para isto, utilizei sinais sintetizados de acordo com a metodologia apresentada no Relatório nº 2 que fiz com João Marcus2. Foi feita a síntese de três sinais de voz, equivalente à vogal /a/, com valores de frequência fundamental ( ) iguais a 110Hz, 205Hz e 300Hz, sendo que esses valores foram escolhidos para representar vozes de homem, mulher e criança, respectivamente. Os valores das formantes que utilizei seguiram o representado na Tabela 1, apresentados em Behlau [1].
) iguais a 110Hz, 205Hz e 300Hz, sendo que esses valores foram escolhidos para representar vozes de homem, mulher e criança, respectivamente. Os valores das formantes que utilizei seguiram o representado na Tabela 1, apresentados em Behlau [1].

Para avaliar os valores estimados realizei o cálculo de duas medidas propostas, em outros trabalhos [2], para a comparação com outros métodos de estimação de formantes.
A primeira medida, sugerida no trabalho de Wang & Quatieri [3], consiste numa avaliação do erro percentual para cada janela entre a -ésima formante do sinal ( ) sintetizado e a respectiva formante estimada (
) sintetizado e a respectiva formante estimada ( ) como segue:
) como segue:
(3) 
Já a segunda medida, sugerida no trabalho de Alku et al. [4], assume um vetor que contenha todas as  formantes do sinal sintetizado
formantes do sinal sintetizado  . Assim, essa medida calcula a distância euclidiana entre esse vetor
. Assim, essa medida calcula a distância euclidiana entre esse vetor  e o vetor
e o vetor  , que contêm as formantes estimadas para a janela avaliada, que é calculada assim:
, que contêm as formantes estimadas para a janela avaliada, que é calculada assim:
(4) 
Mas e como é mesmo esse método? Funcionou bonitinho?
Bem, vamos com calma. A ideia original proposta, que implementei no TCC, para resolver esse problema consiste em estimar o contorno espectral por predição linear de várias ordens e selecionar a maior ordem que obtém uma formante a mais do que o número desejado (aqui, por utilizar uma a mais, a última formante estimada foi ignorada). Para garantir uma menor influência da na análise, utilizei janelas retangulares com duração de  , garantindo uma janela de observação menor que um período do sinal analisado. A contagem de picos foi feita de maneira convencional, utilizando todo o espectro.
, garantindo uma janela de observação menor que um período do sinal analisado. A contagem de picos foi feita de maneira convencional, utilizando todo o espectro.
Por causa da forma em que o processo de síntese foi implementado, o método foi aplicado para a estimação de 3 formantes. Na Tabela 2, estão os valores de erro e distância que obtive para a estimação de formantes utilizando essa abordagem nos sinais sintetizados (média entre as janelas). Apenas para fins de comparação (e para ser um pouco mais humilde), na Tabela 3 encontram-se representados os valores da estimação de formantes para vogais /a/ sintetizadas no método proposto no artigo.

Bem, como deve ter sido possível perceber, esses resultados não foram nada eficientes na estimação das formantes (e podem ter prejudicado significativamente os resultados de classificação). Mas calma, antes que joguem tomates em mim, nem tudo está perdido. Analisando os resultados obtidos, foi possível observar que, em muitas janelas, a estimação para a primeira formante tendia a valores próximos à frequência fundamental. Logo, o uso de janelas pequenas não reduziu suficientemente a influência da , sendo necessária outra estratégia para isso.
Pensando nisso, utilizei uma outra abordagem que havia utilizado em alguns testes anteriores aos do TCC. Essa abordagem consistiu em utilizar o trecho do espectro de frequências maiores que  Hz para a contagem dos picos, buscando assegurar que os picos espectrais proporcionados pela frequência fundamental () não seriam considerados. Os valores obtidos de erro e distância para essa segunda abordagem representados na Tabela 4.
Hz para a contagem dos picos, buscando assegurar que os picos espectrais proporcionados pela frequência fundamental () não seriam considerados. Os valores obtidos de erro e distância para essa segunda abordagem representados na Tabela 4.

Certamente foi possível observar que essa simples alteração da nova abordagem, que buscou eliminar a influência da frequência fundamental na estimação, permitiu uma melhora muito grande no resultado. Entretanto, apesar da melhora significativa observada com a mudança na abordagem, se comparados aos resultados apresentados na Tabela 3, a estimação ainda deixa a desejar. Mais uma vez, analisando os resultados obtidos, foi observada que ainda foi possível observar uma influência da nas estimações para os sinais de 205 Hz e 300 Hz. Foi possível observar também, que em algumas janelas a terceira formante era estimada com valores significativamente mais altos (principalmente para os sinais de 110 Hz).
Vish! Mas e agora, como proceder?
Levando em conta que um dos principais problemas observados nos resultados está no fato de que a influência da na estimação permanece sendo significativa, usar algum recurso mais eficiente para remover essa influência. Note que uma solução simples para esse problema (e, provavelmente, eficiente) é o uso de um filtro passa-altas, que elimine as frequências mais baixas, incluindo a própria . Já os erros de estimação nas frequências mais altas provavelmente estão relacionados à detecção dos harmônicos da frequência fundamental em frequências superiores às formantes. Para isso, limitar a banda de análise à um intervalo de frequência em que haja maior chance de se encontrar as formantes do sinal analisado pode ser uma abordagem que resolva esse problema.
Massa! E quais foram mesmo os artigos e o livro que você citou?
References
- (2001): VOZ – O Livro do Especialista. Livraria e Editora Revinter Ltda., Rio de Janeiro – RJ, 2001, ISBN: 85-7309-525-3.
- (): . .
- (2010): High-pitch formant estimation by exploiting temporal change of pitch. Em: IEEE transactions on audio, speech, and language processing, vol. 18, não 1, pp. 171–186, 2010.
- (2013): Formant frequency estimation of high-pitched vowels using weighted linear prediction. Em: The Journal of the Acoustical society of America, vol. 134, não 2, pp. 1295–1313, 2013.
Deixe um comentário