
[bibshow file=ref.bib]
Objetivos
Realizar a síntese de um sinal de voz com parâmetros conhecidos, utilizando o modelo do pulso glotal proposto por Rosenberg [1] e um filtro IIR (Infinite Impulse Response) para modelar o trato vocal. Esta síntese permitirá fazer uma verificação da eficácia do algoritmo do IAIF [2] implementado, por meio da comparação entre o pulso glotal estimado pelo IAIF e o pulso utilizado para a síntese.
Metodologia
Modelo de Rosenberg para o Pulso Glotal
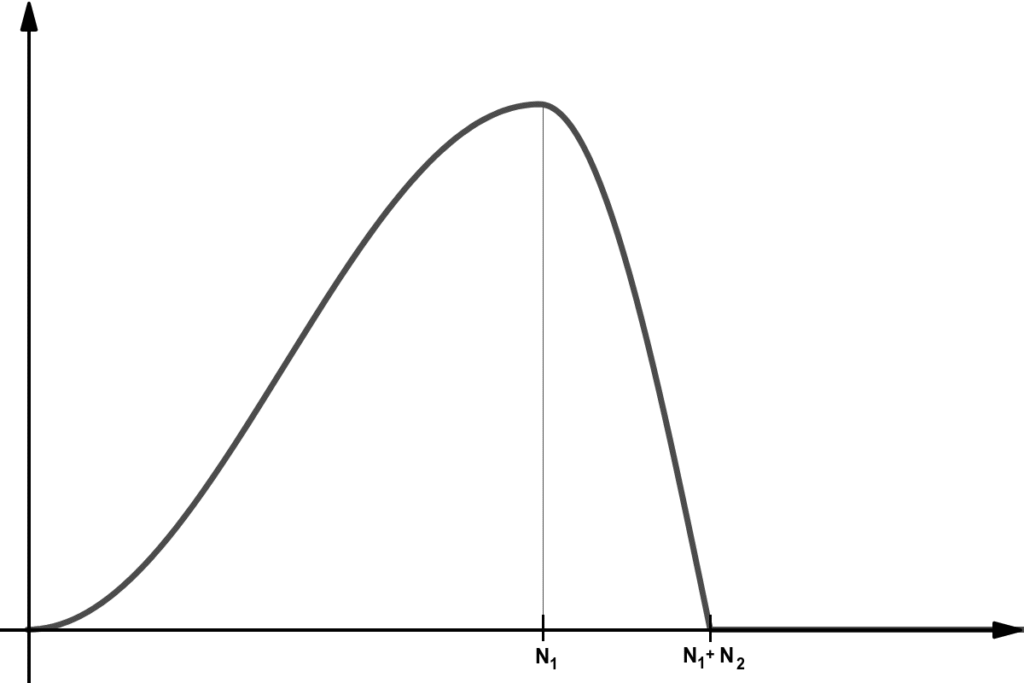
Para modelar o formato de um pulso glotal natural, Rosenberg [3] propôs uma aproximação para sintetizar este pulso utilizando uma função contínua por partes da seguinte forma [4]:
(1) ![\begin{equation*} g[n]=\begin{cases} \frac{1}{2}\left(1-cos\left(\frac{\pi n}{N_1} \right) \right), & 0\leq n \leq N_1\\\\ cos\left(\frac{\pi\left(n-N_1\right)}{2 N_2} \right), & N_1\leq n \leq N_1+N_2\\ 0, & \text{para os demais casos} \end{cases} \end{equation*}](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-10c19d44da46b7f50a20a4f0d8d286ae_l3.png "Rendered by QuickLaTeX.com")
em que  e
e  modelam o tempo de abertura e de fechamento da glote, respectivamente, como ilustrado na Figura 1. Comumente, na literatura,
modelam o tempo de abertura e de fechamento da glote, respectivamente, como ilustrado na Figura 1. Comumente, na literatura,  .
.
Filtro IIR
O Infinite Impulse Response (IIR) é um filtro digital que faz uso de uma realimentação, de modo que a saída é computada com base em seus valores passados e nos valores presentes e passados de sua entrada [5], de acordo com a seguinte equação a diferenças:
(2) ![\begin{equation*} y[n]= \sum_{k=1}^{N} a_k y[n-k] +\sum_{r=0}^{M} b_r x[n-r] \end{equation*}](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-edcae12a7831345b747ba3b21de3d571_l3.png "Rendered by QuickLaTeX.com")
em que N representa o número de polos, M o número de zeros, y é a saída do filtro e x é o sinal de entrada.
A resposta espectral do filtro IIR pode ser obtida a partir da função de transferência do filtro. Esta, por sua vez, é obtida pela aplicação da transformada Z em (2), resultando na seguinte expressão:
(3) 
Foi utilizado um filtro IIR composto apenas por polos, i.e.,  . A escolha desse tipo de filtro se dá pelo fato de que, com exceção de sons nasais e fricativos, o trato vocal pode ser modelado apenas por ressonâncias [6].
. A escolha desse tipo de filtro se dá pelo fato de que, com exceção de sons nasais e fricativos, o trato vocal pode ser modelado apenas por ressonâncias [6].
Procedimento para a Síntese do Sinal
No processo de síntese, primeiramente foi gerado um trem de impulsos em que a distância entre cada impulso corresponde ao período fundamental escolhido. Em seguida, esse trem de impulsos foi convoluído com um pulso glotal de Rosenberg sintetizado. Então, este resultado foi tratado por um filtro IIR, como um modelo de trato vocal, de acordo com o proposto anteriormente, com  . Esta configuração foi utilizada para que houvessem três frequências de ressonância na filtragem, possibilitando a simulação do surgimento de três formantes. Por fim, o sinal de voz sintetizado, resultante da filtragem, foi salvo para ser utilizado na estimação feita pelo IAIF.
. Esta configuração foi utilizada para que houvessem três frequências de ressonância na filtragem, possibilitando a simulação do surgimento de três formantes. Por fim, o sinal de voz sintetizado, resultante da filtragem, foi salvo para ser utilizado na estimação feita pelo IAIF.
IAIF
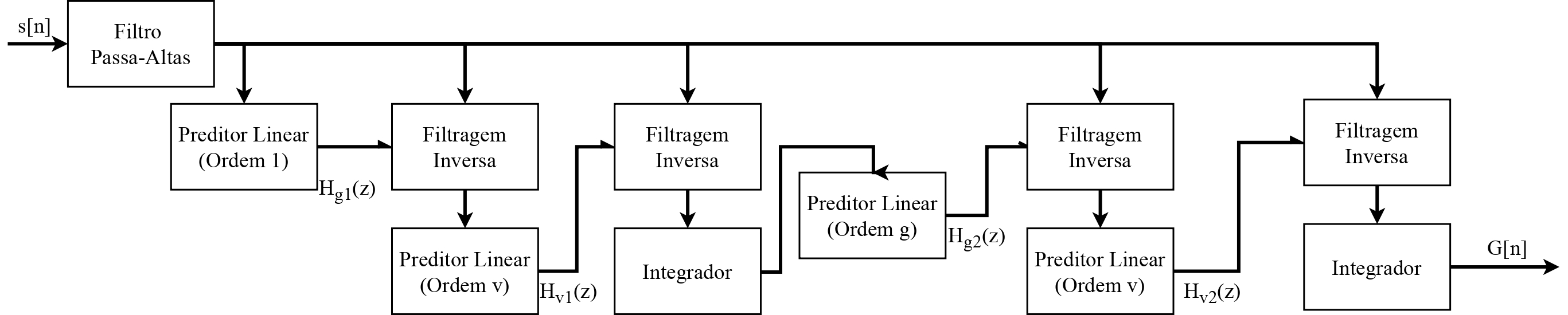
O sinal sintetizado foi utilizado para testar os resultados da implementação do IAIF (Iterative Adaptative Inverse Filtering) [7], de forma que os pulsos glotais sintetizado e estimado puderam ser comparados. O IAIF foi implementado de acordo com a metodologia apresentada no Relatório nº1 e ilustrado na Figura 2.
Resultados
Foi sintetizado, como exemplo para o teste, três sinais de voz com as seguintes frequências fundamentais,  Hz,
Hz,  Hz,
Hz,  Hz (voz de criança, voz feminina e voz masculina, respectivamente). O pulso glotal de Rosenberg foi implementado utilizando valores arbitrários de e , respeitando , de acordo com o representado na Tabela 1.
Hz (voz de criança, voz feminina e voz masculina, respectivamente). O pulso glotal de Rosenberg foi implementado utilizando valores arbitrários de e , respeitando , de acordo com o representado na Tabela 1.

O filtro foi projetado de acordo com o descrito na subseção ??, para , resultando em 3 pares de polos conjugado. Os pares de polos foram ajustados para que as frequências de ressonância fossem equivalentes às formantes da vogal /a/ ( Hz,
Hz,  Hz e
Hz e  Hz, para a voz masculina;
Hz, para a voz masculina;  Hz,
Hz,  Hz e
Hz e  Hz, para a voz feminina;
Hz, para a voz feminina;  Hz,
Hz,  Hz e
Hz e  Hz, para a voz de criança [8]) e os raios de cada par de polos conjugados foram escolhidos como
Hz, para a voz de criança [8]) e os raios de cada par de polos conjugados foram escolhidos como  ,
,  e
e  para todos os sinais. Para representar o sinal sintetizado, foi estimado seu espectro utilizando FFT. Na Figura 3 é possível visualizá-lo junto ao contorno do filtro planejado. Nela, as linhas pretas tracejadas indicam as frequências formantes.
para todos os sinais. Para representar o sinal sintetizado, foi estimado seu espectro utilizando FFT. Na Figura 3 é possível visualizá-lo junto ao contorno do filtro planejado. Nela, as linhas pretas tracejadas indicam as frequências formantes.
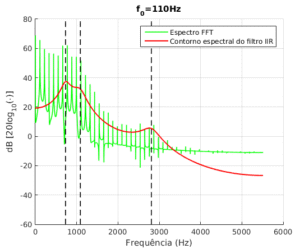
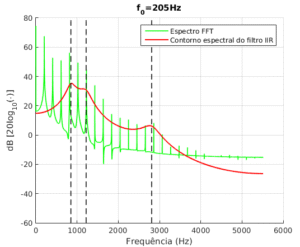
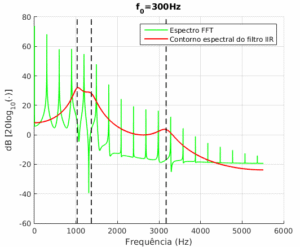
Figura 3 – Representação espectral do filtro implementado e do sinal sintetizado.
Foi utilizado o IAIF com preditores de ordem  e
e  , encontradas de forma empírica de modo a reduzir o erro de estimação, para estimar o pulso glotal do sinal de voz sintetizado. Foi possível observar na estimação do sinal resultante muita sensibilidade à mudança das ordens dos preditores. Para evitar uma flutuação indesejada na saída do sinal, a estimação do pulso foi feita com um pequeno trecho do sinal. Optou-se por utilizar apenas três ciclos do sinal para a estimação. Após a aplicação do método verificou-se um comportamento inesperado na predição linear, de forma que o sinal estimado aparentou estar invertido verticalmente (“de cabeça pra baixo”). Para a comparação com o sinal glotal sintetizado, foi feito um ajuste manual em que o sinal estimado, com a inversão corrigida e normalizado, pudesse ser comparado com o trecho equivalente do sinal sintetizado original. A comparação entre os sinais encontra se representada na Figura 4.
, encontradas de forma empírica de modo a reduzir o erro de estimação, para estimar o pulso glotal do sinal de voz sintetizado. Foi possível observar na estimação do sinal resultante muita sensibilidade à mudança das ordens dos preditores. Para evitar uma flutuação indesejada na saída do sinal, a estimação do pulso foi feita com um pequeno trecho do sinal. Optou-se por utilizar apenas três ciclos do sinal para a estimação. Após a aplicação do método verificou-se um comportamento inesperado na predição linear, de forma que o sinal estimado aparentou estar invertido verticalmente (“de cabeça pra baixo”). Para a comparação com o sinal glotal sintetizado, foi feito um ajuste manual em que o sinal estimado, com a inversão corrigida e normalizado, pudesse ser comparado com o trecho equivalente do sinal sintetizado original. A comparação entre os sinais encontra se representada na Figura 4.
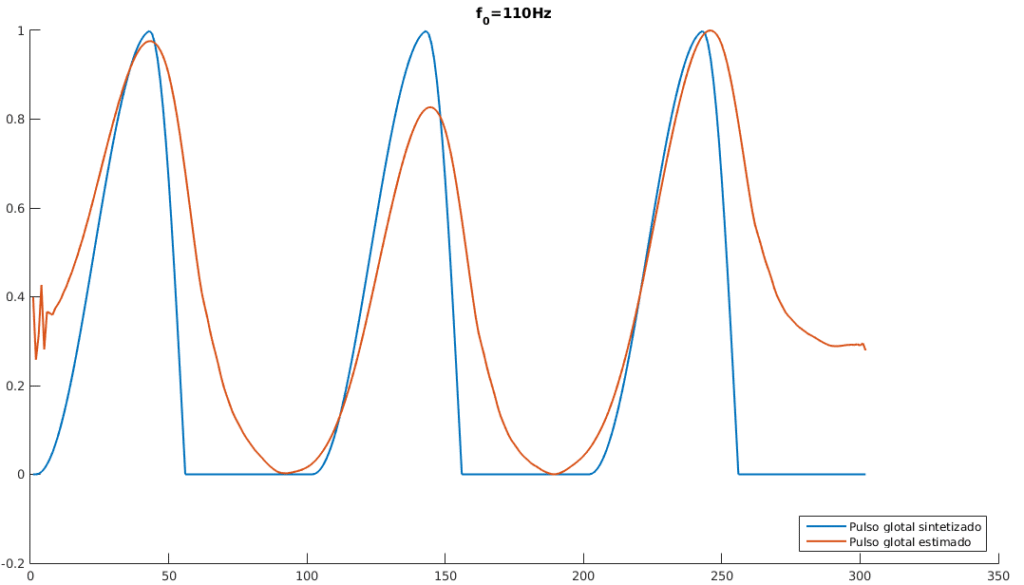
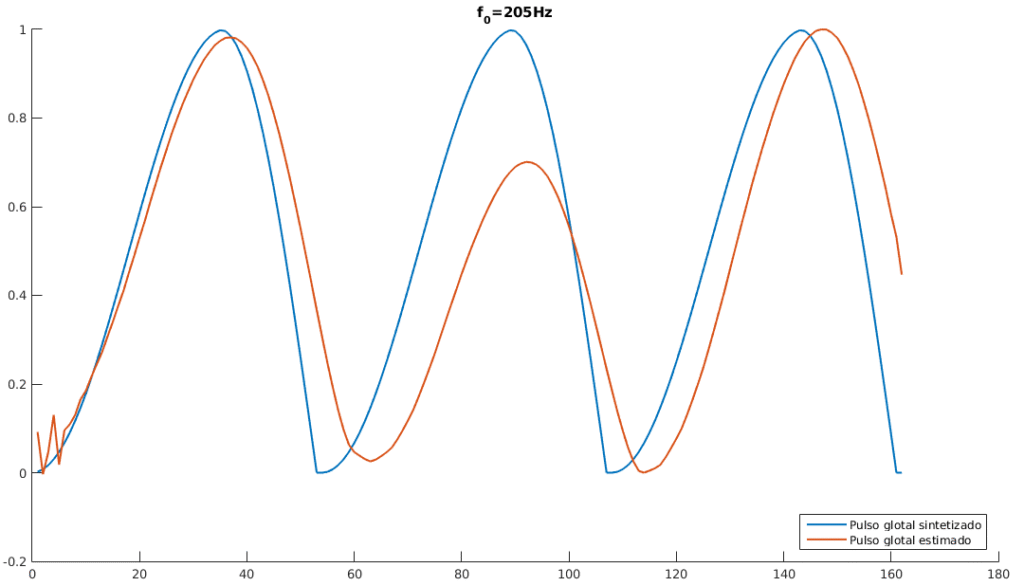
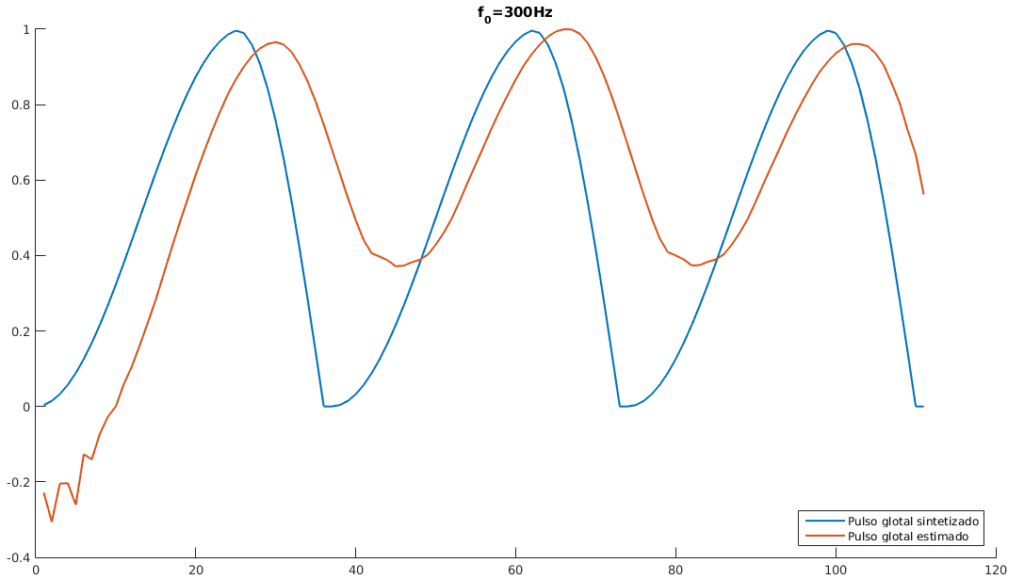 Figura 4 – Comparação entre pulso glotal sintetizado original e pulso glotal estimado para
Figura 4 – Comparação entre pulso glotal sintetizado original e pulso glotal estimado para  Hz,
Hz,  Hz e Hz.
Hz e Hz.
Conclusão e Próxima Etapa
O uso de sinais sintetizados para a implementação do IAIF possibilitou que os resultados da estimação fossem verificados e comparados com o sinal original (o que não seria possível com sinais de voz sem o seu respectivo registro eletroglotográfico). Apesar do sinal estimado pelo IAIF apresentar um comportamento similar ao formato de um pulso glotal, a comparação com o sinal sintetizado permitiu observar que a estimação não representa com precisão o pulso glotal original. A sensibilidade do sinal estimado se encontra em função das ordens dos preditores, e a inexistência de um critério bem definido para o ajuste destas ordens causa problemas quanto a exatidão do método aplicado.
Na próxima etapa do trabalho, pretende-se implementar outro método de estimação de pulso glotal, proposto por Dias e Ferreira [9]. Serão comparados os resultados obtidos com os estimados utilizando o IAIF.
References
- (1971): Effect of glottal pulse shape on the quality of natural vowels. Em: The Journal of the Acoustical Society of America, vol. 49, não 2B, pp. 583–590, 1971.
- (1991): Analysis of glottal waveform in different phonation types using the new IAIF-method. Em: Proc. 12th Int. Congress Phonetic Sciences, pp. 362–365, 1991.
- (1971): Effect of glottal pulse shape on the quality of natural vowels. Em: The Journal of the Acoustical Society of America, vol. 49, não 2B, pp. 583–590, 1971.
- (1978): Digital processing of speech signals. Prentice-Hall, 1978, ISBN: 0-13-213603-1.
- (): . .
- (1971): Effect of glottal pulse shape on the quality of natural vowels. Em: The Journal of the Acoustical Society of America, vol. 49, não 2B, pp. 583–590, 1971.
- (1991): Analysis of glottal waveform in different phonation types using the new IAIF-method. Em: Proc. 12th Int. Congress Phonetic Sciences, pp. 362–365, 1991.
- (2001): Speech science: an integrated approach to theory and clinical practice. Allyn & Bacon, 2001.
- (2014): Glottal pulse estimation–a frequency domain approach. Em: Unpublished, 2014.
Deixe um comentário