
[bibshow file=ref.bib]
Dando continuidade ao método de estimação de formantes baseado na ideia utilizada no TCC e no PIBIC, apresento nesse relatório novos testes que realizei e os resultados que obtive. Tendo em vista a melhoria do que apresentei no relatório anterior, utilizei uma abordagem um pouco mais refinada para a remoção da frequência fundamental – que vinha atrapalhando a estimação das formantes (especialmente a primeira formante).
Ué, mas você não disse que ia fazer uma pausa nos relatórios? O que foi feito dessa vez?
Bem observado de sua parte. De fato, eu havia dito. Mas acabou que as ideias começaram a coçar em minha cabeça e, bem… cheguei até aqui. De uma forma geral, mantive a estrutura do método como apresentado anteriormente, focando as alterações na remoção da influência da frequência fundamental da estimação.
Sim, aquele método! Bem… como ele era mesmo?
Não se preocupe, farei uma breve recapitulação sobre ele. A ideia inicial do método consiste em estimar as formantes utilizando os picos do contorno espectral do sinal. Porém, dependendo do sinal analisado, preditores de mesma ordem podem retornar um diferente número de picos espectrais. Assim propus a utilização de preditores lineares de diversas ordens para uma estimação mais acurada das formantes. Para isso, é escolhido o preditor de maior ordem, que encontre uma formante a mais que o número desejado em seu contorno espectral, para analisar o valor das formantes.
Os sinais sintetizados
Utilizei, para avaliar o resultado da estimação, os mesmos três sinais de voz sintetizados do relatório anterior. Esses sinais são equivalente à vogal /a/, com valores de frequência fundamental ( ) iguais a 110Hz, 205Hz e 300Hz. Os valores das formantes são os representados na Tabela 1, apresentados em Behlau [1].
) iguais a 110Hz, 205Hz e 300Hz. Os valores das formantes são os representados na Tabela 1, apresentados em Behlau [1].

As medidas para avaliar o método
Para avaliar os valores estimados realizei o cálculo das mesmas duas medidas utilizadas no relatório anterior: o erro percentual por formante [2] e a distância euclidiana entre o vetor das formantes e o vetor das formantes estimadas [3].
O resultado anterior

Utilizando a segunda abordagem proposta no relatório anterior (que foi significativamente melhor), em que a contagem dos picos no contorno espectral foi feita no trecho do espectro com frequências maiores que  Hz (para assegurar que os picos espectrais proporcionados pela frequência fundamental não seriam considerados) foram obtidos os valores do erro percentual por formante e da distância euclidiana apresentados na Tabela 2.
Hz (para assegurar que os picos espectrais proporcionados pela frequência fundamental não seriam considerados) foram obtidos os valores do erro percentual por formante e da distância euclidiana apresentados na Tabela 2.
Ah, lembrei! Mas e agora?
Pensando em melhorar a remoção da influência da do sinal, implementei um processo utilizando estimação de por autocorrelação do sinal, predição linear e filtragem inversa. Mas caso esteja perguntando “o que é mesmo isso?”, seus problemas se acabaram! Farei um breve introdução/revisão desses conceitos1.
Estimação de frequência fundamental por autocorrelação
Para estimar a de um sinal, é necessário que a repetição periódica seja detectada. Uma maneira bem simples de fazer isso consiste em utilizar a função de autocorrelação. Assumindo um sinal digital ![x[k]](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-88be78b31528bb450106ef8a8ee13b12_l3.png "Rendered by QuickLaTeX.com") , a função de autocorrelação
, a função de autocorrelação ![\phi[k]](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-c8e43f3405fb4645c12fa7821adab01c_l3.png "Rendered by QuickLaTeX.com") desse sinal é dada pelo produto interno de um sinal com ele mesmo defasado em
desse sinal é dada pelo produto interno de um sinal com ele mesmo defasado em  amostras, como mostrado na seguinte equação [4]:
amostras, como mostrado na seguinte equação [4]:
(1) ![\begin{equation*} \phi[k]=\sum_{m=-\infty}^{\infty} {x[m]x[m+k]}. \end{equation*}](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-7d0d05287ca3b4bd28a66e7a13d941e9_l3.png "Rendered by QuickLaTeX.com")
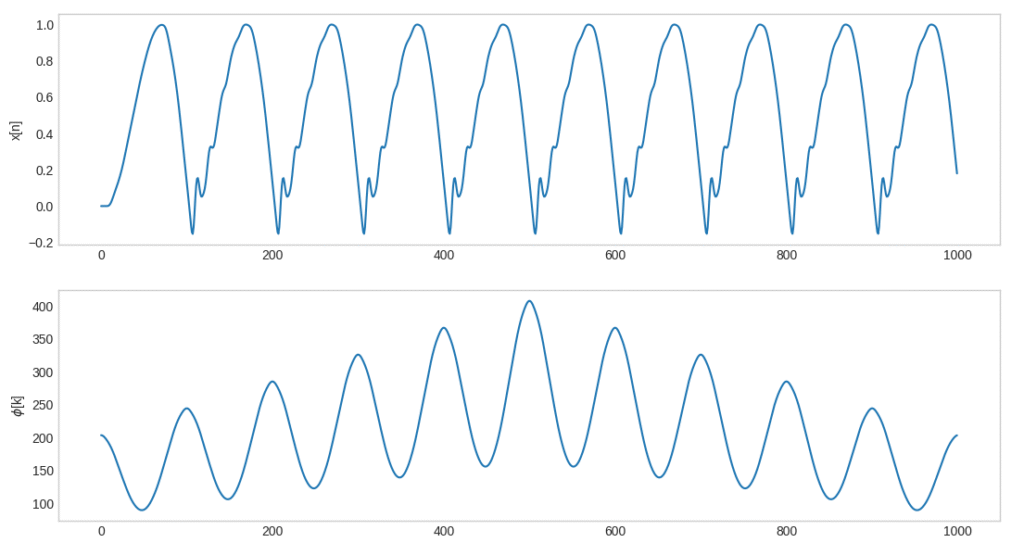
Aqui é possível observar que o valor máximo desse função é atingido quando  . Porém, quando a autocorrelação é calculada com um sinal periódico, a função de autocorrelação vai ser periódica com o mesmo período do sinal, i.e., para
. Porém, quando a autocorrelação é calculada com um sinal periódico, a função de autocorrelação vai ser periódica com o mesmo período do sinal, i.e., para  (onde
(onde  é o período e
é o período e  é um número inteiro qualquer),
é um número inteiro qualquer), ![\phi[0]=\phi[k]](https://www.biochaves.website/wp-content/ql-cache/quicklatex.com-288e4288a699e93124f21d55a7380ced_l3.png "Rendered by QuickLaTeX.com") . Como o sinal de voz não é exatamente algo que possamos chamar de periódico, podemos estimar o período do sinal observando o segundo maior pico do sinal de autocorrelação (o maior pico equivale a ). O valor de k que fornece esse pico equivale ao período (em amostras) do sinal. Assim, conhecendo o período e a taxa de amostragem do sinal, podemos estimar a .
. Como o sinal de voz não é exatamente algo que possamos chamar de periódico, podemos estimar o período do sinal observando o segundo maior pico do sinal de autocorrelação (o maior pico equivale a ). O valor de k que fornece esse pico equivale ao período (em amostras) do sinal. Assim, conhecendo o período e a taxa de amostragem do sinal, podemos estimar a .
Na Figura 1 ilustrei um sinal e seu respectivo sinal de auto correlação e gerei uma ilustração animada do processo de calculo do sinal de auto correlação pra um sinal, disponível no link: https://www.youtube.com/watch?v=LMbIj9B5MfI.
[embedyt] https://www.youtube.com/watch?v=LMbIj9B5MfI[/embedyt]
Filtragem Inversa
O processo de filtragem inversa nada mais do que literalmente “inverter” um filtro para anular seu efeito no sinal, “transformando” polos em zeros e vice-versa. Assim, se quisermos remover a influência exercida por um filtro  de um sinal que foi filtrado por ele, basta utilizar um filtro
de um sinal que foi filtrado por ele, basta utilizar um filtro  , dado como segue:
, dado como segue:
(2) 
Sei que isso parece completamente nada a ver com o ponto que se deseja chegar com esse relatório, mas peço que tenha calma. Logo vai dar pra entender (eu espero).
Ok então, estou calmo. Como você usou isso tudo pra melhorar o resultado?
Bem, inicialmente pensei em estimar a do sinal utilizando autocorrelação e daí passar o sinal por um filtro passa-altas com frequência de corte um pouco maior que a própria . Porém, poupá-los-ei2 de mais uma tabela e já adianto que os resultados obtidos dessa forma não foram bons. O porque desses resultados não terem sido bons, sinceramente, eu ainda não sei.
Entretanto, após ter chegado nesse resultado, pensei em uma outra forma de remover a influência da fundamental, sem remover outros componentes de frequência do sinal. Tendo estimado a , passei o sinal por um filtro passa-faixa de banda estreita (100Hz de banda passante) centrado na . Em seguida, apliquei um preditor linear de segunda ordem ao sinal filtrado e, com os coeficientes estimados pelo preditor, apliquei filtragem inversa no sinal original para remover, assim, a influência da . Por fim, apliquei o processo proposto no relatório anterior, para estimar formantes, no sinal resultante da filtragem inversa. Todo esse processo pode ser representado pelo diagrama de blocos ilustrado na Figura 2. A Figura 3 exemplifica o efeito da filtragem inversa, removendo o efeito da no contorno espectral estimado.
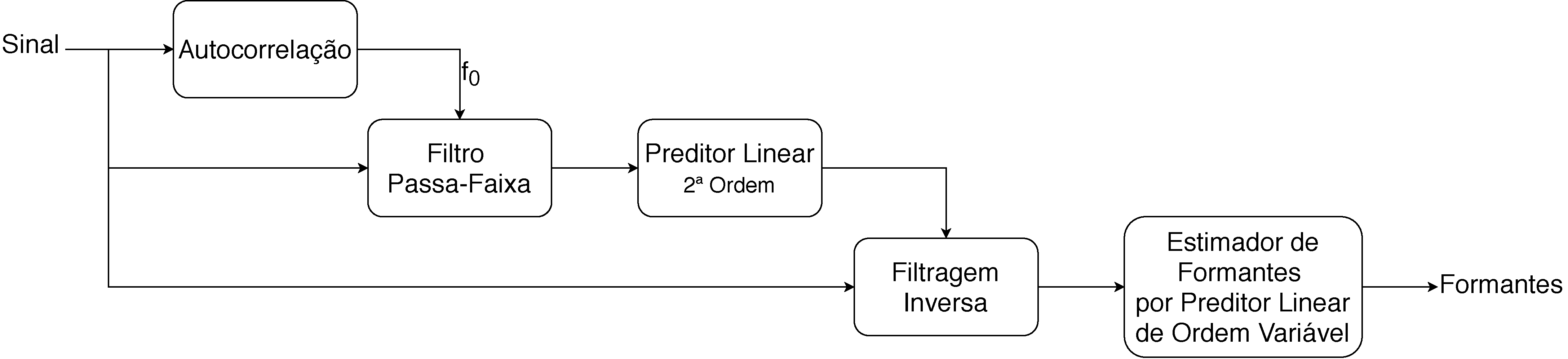
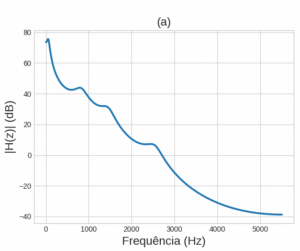

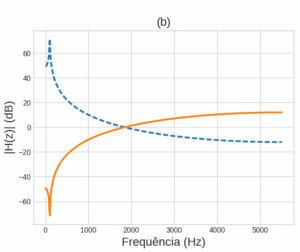

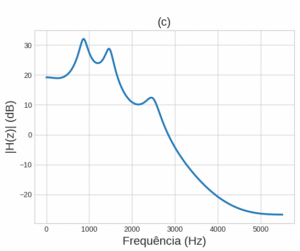
Figura 3 – Exemplo do efeito da filtragem inversa na estimação do contorno espectral: (a) Contorno espectral de um sinal, estimado por um preditor linear de ordem 10; (b) Contorno espectral estimado para o sinal que passou pelo filtro passa-faixa centrado na do sinal, representado em azul tracejado. O sinal de (a) é então passado pelo filtro inverso, cujo contorno espectral é representado pela linha laranja; (c) Contorno espectral do sinal resultante da filtragem inversa, estimado também com um preditor de ordem 10.
Os resultados que eu obtive utilizando essa nova proposta encontram-se representados na Tabela 3. Nela podemos observar uma melhora significativa na estimação das formantes. Assim como no relatório anterior, na Tabela 4 estão representados os resultados do trabalho de Alku et al. [5] para fins de comparação.

Caramba, melhorou bastante mesmo! E agora, quais os próximos passos?
De fato, os resultados foram bem satisfatórios dessa vez. Para a continuidade do trabalho, tem dois pontos aos quais creio que seja necessário dispensar atenção a partir daqui:
- Realizar os testes com uma maior quantidade e maior variedade de sinais: Nos testes implementados até aqui utilizei apenas 3 sinais de voz, sintetizando apenas a vogal /a/. Para uma melhor análise dos resultados, vai ser importante testar o método com vários sinais, havendo entre eles a síntese de todas as vogais.
- Implementar outros métodos e comparar: Utilizando os mesmo sinais utilizados para o teste do método proposto3, pretendo implementar e testar o método proposto por Alku et al. [6] e outros métodos de outros trabalhos para uma comparação mais adequada e completa com os resultados obtidos pelo método aqui apresentado.
Além desses dois pontos que receberão um maior foco daqui pra frente, também creio que seja válido retornar ao classificador que implementei no TCC4, utilizando o novo método para a estimação de formantes e verificar a influência da mudança nos resultados. Porém, como havia pretendido anteriormente, farei uma pausa por agora e somente mais pra frente voltarei a fazer relatórios.
Hum, sei… Mas e quais foram mesmo as referências?
References
- (2001): VOZ – O Livro do Especialista. Livraria e Editora Revinter Ltda., Rio de Janeiro – RJ, 2001, ISBN: 85-7309-525-3.
- (2010): High-pitch formant estimation by exploiting temporal change of pitch. Em: IEEE transactions on audio, speech, and language processing, vol. 18, não 1, pp. 171–186, 2010.
- (2013): Formant frequency estimation of high-pitched vowels using weighted linear prediction. Em: The Journal of the Acoustical society of America, vol. 134, não 2, pp. 1295–1313, 2013.
- (1978): Digital processing of speech signals. Prentice-Hall, 1978, ISBN: 0-13-213603-1.
- (2013): Formant frequency estimation of high-pitched vowels using weighted linear prediction. Em: The Journal of the Acoustical society of America, vol. 134, não 2, pp. 1295–1313, 2013.
- (2013): Formant frequency estimation of high-pitched vowels using weighted linear prediction. Em: The Journal of the Acoustical society of America, vol. 134, não 2, pp. 1295–1313, 2013.
- Para não me estender muito, não revisarei a predição linear, que já foi bastante explicada e reexplicada em vários relatórios do grupo (em caso de dúvidas, consulte o médico e leia o relatório anterior).
- Mesóclises são maravilhosas. Usá-las-ei com certeza!
- Se ele for realmente útil, vai precisar de um nome.
- Classificador de Qualidade Vocal em Escalas de Avaliação Perceptivo-Auditiva.
Deixe um comentário