
Relatório 5 – Biochaves
Luiz Miranda Cavalcante Neto
Olá a todos os biochaveiros. Eu, também biochaveiro, passo aqui neste relatório para dizer que eu venho fazendo besteira a algum tempo e não sabia. Pois é, programar tem dessas coisas, um erro passa de fininho por entre seus dedos e você só encontra ele depois que já nem liga mais pra nada, quando já está indo dormir, ou quando tem uma apresentação para fazer para daqui a três dias. Como esse já é o segundo erro deste tipo que cometo e apresento em relatório, tomo a liberdade de parafrasear a famosa filósofa Britney Spears e dizer Oops, I did it again! Vamos ao relato.
Relembrando:
Para meus queridos leitores que se esquecem das coisas, assim como eu, vou relembrar o que estava acontecendo, se você leu os relatórios anteriores a pouco tempo, pode pular esta parte.
Até o momento, eu estou a modelar cada artista usando uma matriz de transição entre acordes. As linhas dessa matriz representam sequências de N acordes extraídos das músicas do artista e as colunas representam os acordes que aparecem logo após a respectiva sequência. Para simplificar o processamento são considerados apenas 24 acordes, sendo eles: A, A#, A#m, Am, B, Bm, C, C#, C#m, Cm, D, D#, D#m, Dm, E, Em, F, F#, F#m, Fm, G, G#, G#m, Gm. Assim, se N = 3, a quantidade de linhas da matriz deve ser de 24x24x24 = 13824 (já que a matriz deve conter todas as combinações possíveis entre os acordes) e a quantidade de colunas é independente de N. Desta forma, cada artista será representado por uma matriz 13824 x 24 em que cada elemento representa a probabilidade de um dos 24 acordes aparecer depois que a sequência representada pela linha ocorrer.
Feito isso, juntei os modelos de 100 artistas em uma matriz de dados e reduzi suas dimensões usando PCA, MDS e a decomposição SVD. Plotei esses valores reduzidos e os resultados foram todos igualmente esquisitos e podem ser visualizados nos relatórios passados, ou nas descrições mais abaixo.
Relembrou tudo? Bom, vamos agora aos problemas.
Os problemas
Aqui eu descrevo os problemas que encontrei.
O problema 1
Como você pode ver na Figura 1, os resultados dos experimentos seguem a sequência de quantidade de dados em cada artista, ou seja, quanto mais dados (tamanho do arquivo) mais longe dos outros dados o ponto estará.
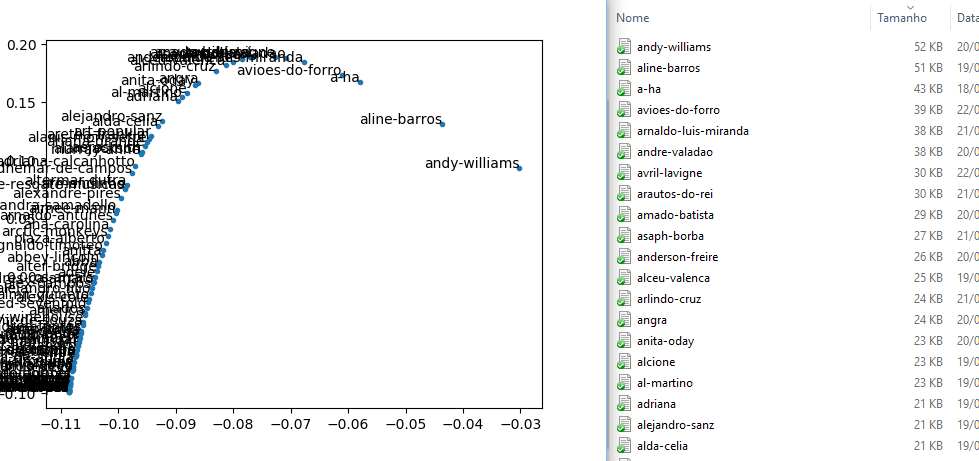
Figura 1. Correlação entre posição do artista e o tamanho do arquivo com os seus acordes.
Com certeza isso é problema de quantidade de dados não é?! A resposta vem mais pra frente neste relatório, mas vou dar um spoiler, não é! Enfim, os dados não deveriam se comportar desta forma. É cientificamente feio esperar que seus dados se comportem de uma forma e buscar uma correção para que eles se comportem como você espera. Com isso em mente, deixei isso de lado por um tempo e fui trabalhar em outras coisas até que surgiu o problema 2.
O problema 2 (Não é um problema de verdade, só uma motivação a mais para trabalhar)
Como todos, ou muitos, sabem, nosso grupo irá apresentar o que está sendo desenvolvido pelos seus integrantes na sexta-feira 14/12/2018, e eu me ofereci para ser um dos que irão se apresentar. Ao fazer isso, não lembrei que estava travado no desenvolvimento. Não queria apresentar algo que não parecia ter para onde ir, então fui buscar uma solução para isso antes de preparar a apresentação. Essa solução surgiu depois de uma investigação.
A investigação
Sabendo o quão ~bom~ programador eu sou, resolvi rever todos os meus códigos, linha por linha. Com exceção da bagunça, nada parecia estar errado. Esse é o perigo!
Processar quantidades muito grandes de dados tende a ser demorado, como estava usando Ngrams com N = 3 isso tendia a acontecer bastante, demorar. Resolvi, então, usar um N = 2, só para conseguir fazer mais testes em menos tempo. Os resultados deveriam ser coerentes com N = 3, e foram, continuava tudo estranho.
Teste vai, teste vem e nada de encontrar erro. Foi então que resolvi observar os modelos de cada artista individualmente. Fiz isso usando a função imshow() e obtive imagens semelhantes às exibidas na Figura 2. Se você ampliar o documento que está lendo, verá padrões diagonais nos modelos, esses padrões são repetições do mesmo acorde, por exemplo: A A A, B B B. Isso não deveria estar acontecendo, pois é muito comum os acordes variarem durante a música, e este modelo diz que é quase improvável que exista transição entre acordes. Foi então que resolvi ver o trecho de código que gerava essa parte do modelo. Lá estava o primeiro erro!
Para seguir esse parágrafo, considere uma música fictícia composta apenas da seguinte sequência de acordes: D A C E F. Para gerar a matriz modelo eu organizo os acordes da música em um vetor em que as posições seguem a ordem de aparição na música. Em seguida, escaneio esse vetor com janelas de N elementos e gravo o acorde que aparece após a janela, assim preencho a matriz de transição que gera o modelo. Neste caso a primeira janela seria D A e gravo o acorde C, em seguida tenho a janela A C e gravo o acorde E, e por aí vai. No meu código, não sei por que cargas d’água, eu estava gravando o segundo elemento da janela e não o elemento que aparece logo após a janela. Corrigi isso e obtive os modelos presentes na Figura 3.

Figura 2. Modelos com erro 1 dos 4 artistas com mais dados.
Que bom! Um erro encontrado, um erro corrigido. E aí, resolveu o problema da Figura 1? Vou poupar vocês de mais uma figura feia e dizer que Não! O gráfico final ainda se parecia com a Figura 1. Vamos a mais investigação.
Desta vez resolvi observar os modelos usando a função imagesc(), para ver se percebia algo a mais. O resultado desta observação pode ser vista na Figura 4. Muito melhor de enxergar as coisas né?! Então, é mesmo, inclusive, você pode até perceber que tem uns padrões se repetindo não é? A diagonal do modelo vai ficando cada vez mais marcada não é? Aí você talvez, jovem sagaz, já tenha pensado no erro que eu cometi. Você está zerando a matriz de transição no início da análise de cada artista?! Então …… eeer….. não estava ?. Agora estou ?. Esse foi o erro 2.

Figura 3. Modelos com erro 2 dos 4 artistas com mais dados.
O que estava acontecendo, no final das contas, era que o código estava pegando o primeiro artista, gerando o modelo correto, esse modelo era somado ao modelo do segundo artista, que já estava errado, e esse erro ia se propagando até o último artista. Coube que, o primeiro artista era o com mais dados, o segundo era o segundo com mais dados, e por aí vai. Isso acontecia por causa do modo que eu separava os X artistas com mais dados para fazer a análise, usando um sort baseado no tamanho do arquivo. Então, na verdade, a Figura 1 não está 100% errada, só 99%, já que um dos artistas está no lugar certo.
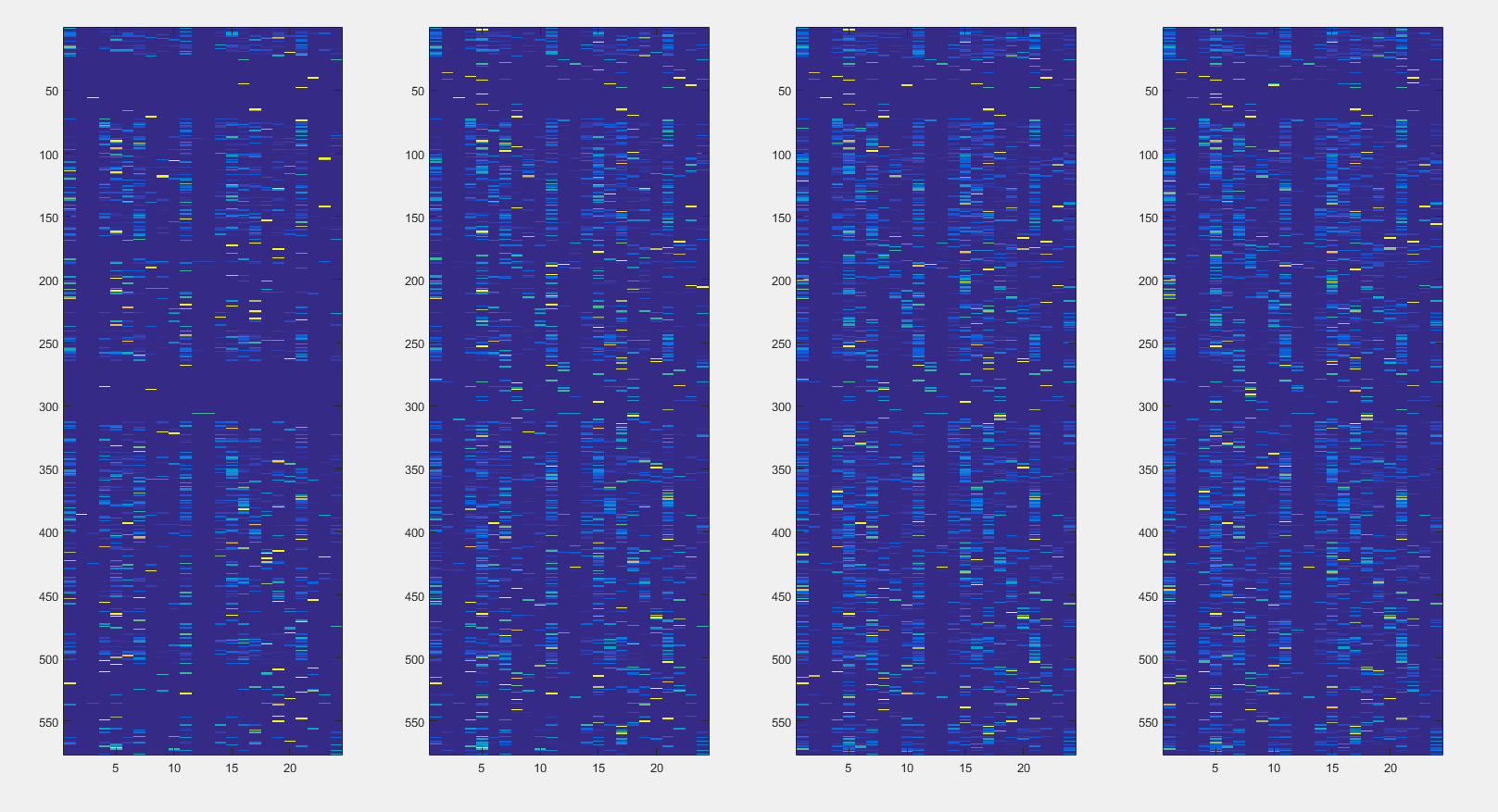
Figura 4. Figura 3 visualizada com a função imagesc().
Após corrigir esses dois erros medonhos, obtive a imagem correspondente à Figura 5. Esta, definitivamente não está ordenada de acordo com o tamanho dos arquivos, eu acho. Dê uma ampliada que você verá algumas coisas que “fazem sentido” como ver Alcione e Arlindo Cruz juntos, ver ACDC e Alice in Chains, Avril Lavigne e Avantasia. Eu sei que já fiz comparações assim antes com outro gráfico, mas dessa vez não tem plot twist. Pelo menos não nesse relatório. No mais, agora vamos focar nas apresentações de sexta. Analisemos esse plot na reunião por favor.
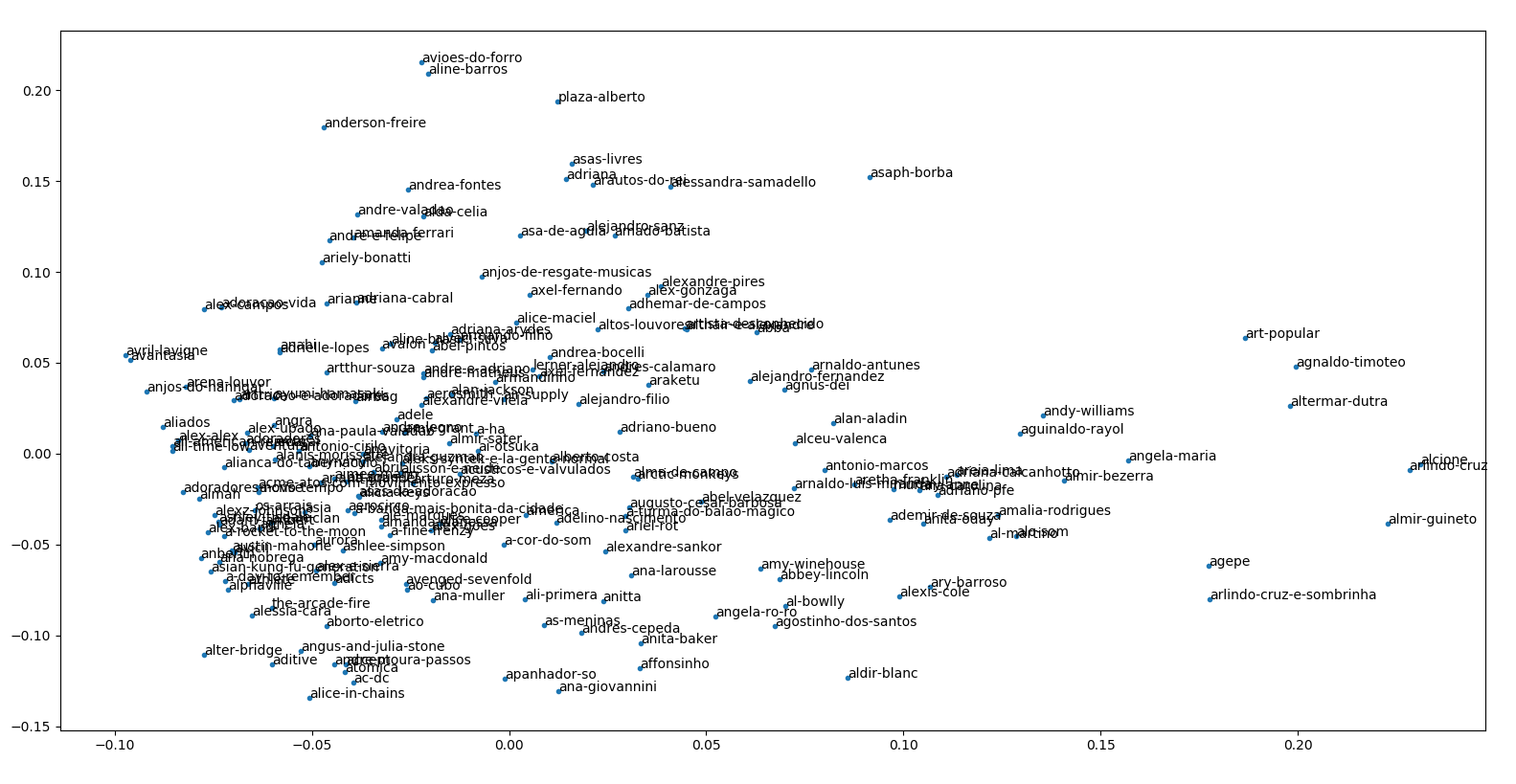
Figura 5. O resultado das correções dos erros 1 e 2.
O que aprendemos com o episódio de hoje? Não confiem nos seus códigos!
Deixe um comentário