
Relatório 4 – Biochaves
Luiz Miranda Cavalcante Neto
Olá alunos, como vão suas férias? Bem? Que bom. Este relatório será um pouquinho mais longo que o normal porque semana passada não rolou, aí vai vir tudo acumulado. Então aproveitem a leitura. Vamos lá.
Recapitulando, ou Direto do túnel do tempo: No último relatório (o 3) descobri que estava modelando os artistas de forma errada. Também falei na última reunião (show show), que estava implementando o MDS. Surpresa surpresa, resolvi o problema do modelo e achei outro problema (descubra qual é após os comerciais), e o MDS foi implementado.
O problema do modelo
Anteriormente, eu havia implementado os modelos dos artistas da seguinte forma:
- Abre a base de acordes do artista;
- Escaneia a sequência de acordes e gera dicionário de acordes ao mesmo tempo;
- Enquanto escaneia, gerar tabela de transição em que as linhas são os Ngrams encontrados e as colunas são os acordes que aparecem logo após o Ngram;
- Depois de muito trabalho duro (do computador) conseguir obter uma tabela de transição normalizada para usar como modelo.
Onde está o problema?, você me pergunta. Se você já leu o relatório 3, já sabe a resposta, mas para os apressadinhos que pularam direto para este texto eu respondo: Nem todas as possíveis combinações de acordes vão aparecer quando a tabela de transição é gerada apenas com os acordes de um artista só. Aí os modelos terão quantidades de linhas e colunas diferentes para cada artista, o que faz esse modelo ser nada modelo.
Solução: Descobrir todos os acordes que aparecem em todos os artistas, computar todas as combinações possíveis entre eles e com isso gerar uma tabela modelo definitiva.
Problema da solução: Após uma rápida análise dos acordes de todos os artistas, descobri que existem cerca de 1500 acordes únicos na base de dados. Se eu usar um N (dos Ngrams) igual a 3 (o que é bem razoável) vamos ter bastante combinações possíveis. Mais precisamente 1500x1500x1500 que é um número bem grande, que eu vou chamar de GPC (GPC = 3,3375×106). Esse número é a quantidade de linhas da matriz de transição, a quantidade de elementos dela será GPCx1500 que um número maior ainda, que eu vou chamar de MGPC (MGPC = 5,0625×1012). É… é muita coisa para um computador computar para apenas um artista.
Solução do problema da solução
Felizmente, nosso grupo possui muitos conhecedores de música (eu não sou um deles). Em reuniões anteriores, Jugurta e Jânio comentaram sobre ignorar os Acidentes musicais. Eu não segui essa sugestão porque não parecia importar tanto (mas você viu acima que importa).
Mas vamos com calma. Antes que você, desconhecedor musical, me pergunte, eu respondo. Acidentes musicais são variações nos acordes que não influenciam tanto no seu som. Por exemplo: Um A#7/E8 pode ser substituído por um A# sem muito dano à melodia. Da mesma forma que quando você calcula um resistor de 1,67K mas só tem de 1,5K no seu estoque. É diferente, mas é a mesma coisa.
Então, o que você fez afinal? Defini que só podem existir 24 acordes chamados acordes “sem frescura”, ou como sigla acordes sf (na função tiraAcidentesTodo.py que vocês podem acessar nesta nota de rodapé). São eles: A, A#, A#m, Am, B, Bm, C, C#, C#m, Cm, D, D#, D#m, Dm, E, Em, F, F#, F#m, Fm, G, G#, G#m, Gm.
Com esses acordes “sem frescura” é possível computar todas as combinações possíveis entre eles com muito mais folga de memória. Façamos as contas: 24x24x24 = 13824, sendo esse o número de linhas da matriz de transição. O número total de elementos dessa matriz será 13824×24 = 331776 (7,92MB), que qualquer raspberry pi consegue computar.
Com a solução do problema da solução encontrada, gerei os modelos dos 100 artistas com mais acordes na base de dados da letra A. Esses modelos podem ser encontrados aqui:
https://www.dropbox.com/sh/a8fgvilnyqxvrbt/AADG4VkgtcmaXvpUYklqvrPRa?dl=0
Esses modelos foram, então, preparados para terem suas dimensões reduzidas. Este processo será descrito na próxima seção.
A próxima seção, reduzindo dimensões
Dois métodos de redução de dimensão foram usados nesta etapa: SVD e PCA (que é um jeito mais bonito do SVD). Antes de entrar a fundo sobre os métodos é preciso mostrar como os modelos foram tratados para terem suas dimensões reduzidas. Vamos ver como foi.
*Tratando os modelos
Acho que boa parte de quem está lendo (você) já trabalhou com algum problema de reconhecimento de padrões. Então, o padrão de como os dados são mostrados nesses problemas são, em geral, uma matriz de dados sendo que cada linha representa uma amostra e cada coluna representa uma característica dessa amostra (dimensões).
Os modelos de cada artista são representações desses artistas de acordo com os dados extraídos sobre ele, então cada artista deve ser uma amostra. E as características do artista, o que são? São os elementos do modelo, cada célula da matriz de transição. Mas… uma matriz não é uma linha de características, são várias linhas. Exatamente, mas é bem simples converter uma matriz com várias linhas em um vetor linha com muitas colunas, basta colocar cada linha da matriz à direita da linha anterior, ou usar o comando reshape (existente em python e matlab). Da uma olhada na Figura 1 que lá está mais claro.
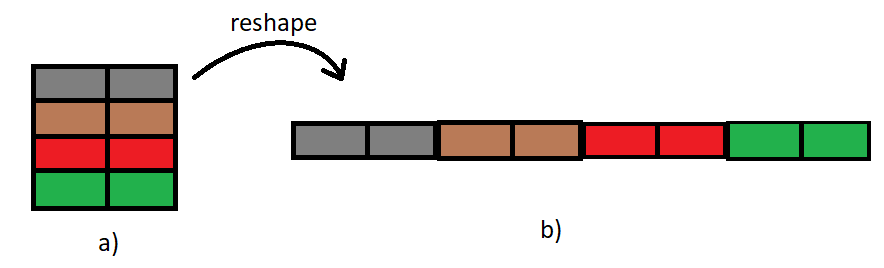
Figura 1. a) Matriz 4×2. b) Matriz após o comando reshape(1,8)
Após o remanejamento da matriz do modelo, podemos agora tratar cada artista como uma amostra e o problema vira um caso clássico de reconhecimento de padrões. Desta forma, quando formos analisar os dados dos artistas teremos uma matriz de dados em que cada linha possui 331776 elementos que representam as características do artista. No experimento, que irei descrever mais a frente, analisei 100 artistas, então a matriz de dados tem 100 linhas e 331776 colunas.
Agora sim, os métodos de redução de dimensão
Como você já leu, usei dois métodos para reduzir as dimensões dos modelos: SVD e PCA.
SVD (mais sobre isso no relatório 2)
No SVD é feita uma segmentação da matriz de dados (vou chama-la de A que tem dimensões = 100×331776) em 3 outras matrizes. São elas: A matriz U de tamanho 100×100, a matriz “diagonal” 100×331776 e a matriz V de tamanho 331776×331776.
Na matriz U, cada coluna corresponde a um vetor característico da nossa matriz de dados A. Na matriz V, cada linha corresponde a um vetor característico de A. E na matriz S cada posição da diagonal principal correlaciona uma coluna de U com uma linha de V, além disso, esses valores podem ser usados como medida de importância para cada elemento de U e V. Na Figura 2 pode ser vista uma ilustração dessa decomposição.
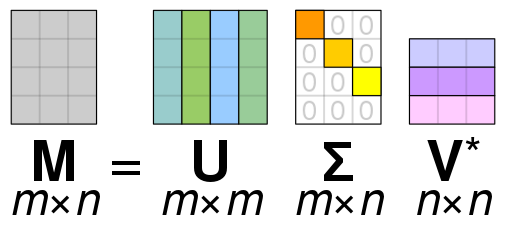
Figura 2. Ilustração da decomposição SVD. M é a nossa matriz A e Σ é a nossa matriz S [1].
Com a decomposição feita, podemos usar os dois vetores (colunas) mais fortes da matriz U como coordenadas para nossos artistas.
PCA (Principal Component Analysis)
A análise de componentes principais é um método de análise de dados que usa como fonte de análise a covariância da matriz de dados. Sua principal aplicação é a redução de dimensões dos dados, e é para isso que ela foi usada aqui.
O procedimento de aplicação do PCA é o seguinte:
- Computar a matriz de covariância C da matriz de dados A;
- Calcular os autovalores e autovetores da matriz C;
- Ordenar os autovalores em ordem decrescente;
- Selecionar K os autovetores correspondentes aos maiores autovalores, sendo K o número de dimensões que deseja-se manter;
Com os autovetores selecionados podemos usar cada um deles como um eixo do gráfico que irá representar nossos dados. No caso deste trabalho foi usado K=2.
Agora que já conhecemos os dois métodos vamos dar uma olhada nos resultados.
O experimento
Para testar minha hipótese implementei o seguinte experimento:
- Selecionei os 100 artistas com mais acordes extraídos na base de dados da letra A;
- Extrai os modelos de todos eles;
- Organizei os modelos em uma matriz de dados A [100×331776];
- Fiz com que A tivesse apenas 2 dimensões usando PCA e SVD;
- Plotei os gráficos da matriz A reduzida usando os dois métodos.
Agora sim, vamos aos resultados.
Os resultados
São esses aí na Figura 3.
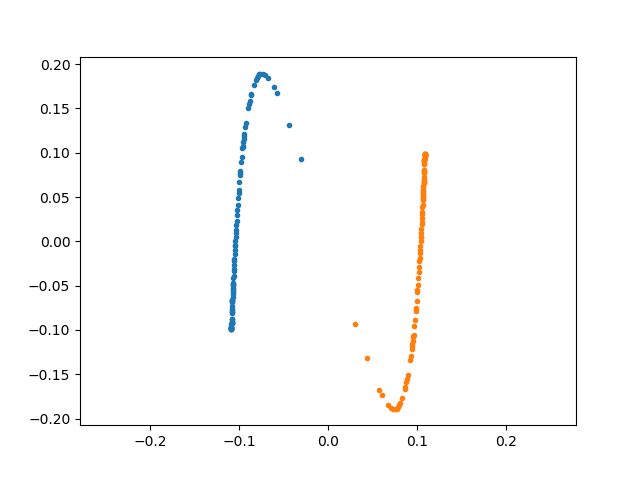
Figura 3. Resultados, em azul usando SVD e em laranja usando PCA.
Ué?! É o mesmo gráfico só que espelhado? Eu esperava que você fosse me questionar por outra coisa, mas… sim, é o mesmo gráfico um espelhado em relação ao outro. O PCA é filho-sobrinho do SVD, tem que dar resultados parecidos mesmo, o espelhamento é só discrepância no modo como os dados foram apresentados aos algoritmos. Mas o problema principal não é esse. E qual é? O fato de não ter informação nenhuma nesses gráficos? Cadê os nomes dos artistas? Cadê os agrupamentos? Então, o principal problema aparece na Figura 4.
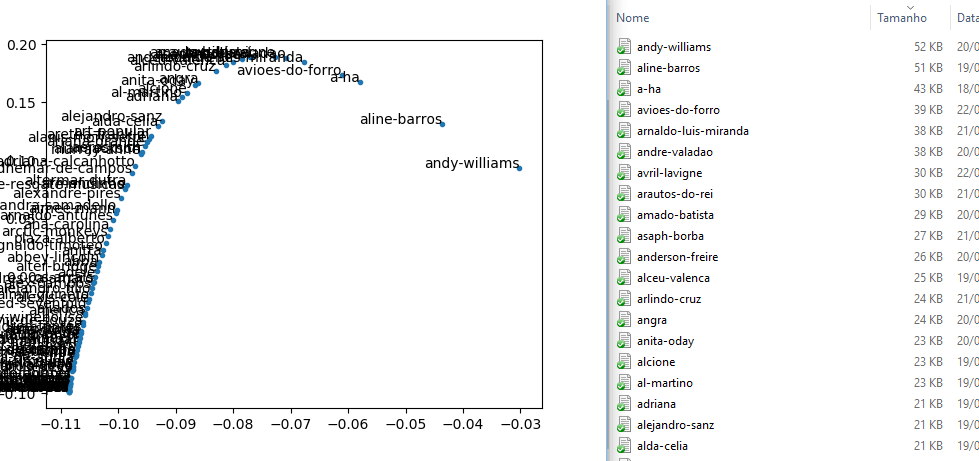
Figura 4. Esse é o problema.
O problema é que, no gráfico os artistas estão aparecendo mais à direita (no SVD) quando o tamanho do seu arquivo da base é maior. E observando mais de perto isso sempre acontece. É como se esse código fosse um algoritmo de sort ao invés de redutor de dimensões. Pois é, por enquanto não tenho solução para este problema, então eu pergunto aos universitários (e pós doutores): o que parece estar acontecendo?
Minha suspeita é de que as matrizes dos modelos sejam esparsas demais para conseguir extrair alguma informação sobre as características dele, aí a única característica que os redutores de dimensão encontrar é o tamanho de cada arquivo.
Como sempre, meus códigos estão à disposição de vocês, pelo link:
https://www.dropbox.com/sh/m47077fkzb5xhdw/AACo0ZiypVjfCUV57KdBKjV7a?dl=0
Não tem Beatles nesse gráfico, mas eu preciso dum Help
Referências
[1] https://en.wikipedia.org/wiki/Singular_value_decomposition#/media/File:Singular_value_decomposition_visualisation.svg
Deixe um comentário