
Relatório 1 – Biochaves
Luiz Miranda Cavalcante Neto
Observação importante: Este texto inicial não contém referências pois até o momento foquei exclusivamente em implementar os códigos referentes à ideia inicial do que desejo fazer. Então, querido leitor, leia esses “fatos” com um pé atrás, pois foi tudo graforréia da minha cabeça em conjunto com as idéias extraídas das reuniões anteriores.
Ao ouvir uma música, é muito comum que as pessoas automaticamente reconheçam o estilo desta melodia (ou pelo menos tenham uma idéia). O arcabouço musical que a pessoa agrega, até o momento que ela ouve a música em questão, é a principal fonte para essa classificação. Em geral, pessoas que ouviram mais músicas conseguem discernir melhor entre estilos.
O maravilhoso mundo que vivemos hoje nos permite fazer com que computadores façam boa parte dos trabalhos que não gostamos de fazer (e alguns que gostamos de fazer também). Aproveitando que somos engenheiros (ou quase isso) e sabemos mandar os computadores fazerem coisas por nós, podemos designar mais uma tarefa a eles: Ouvir todas as músicas possíveis e classificar os artistas em gêneros musicais. Mas para que isso se os próprios artistas já se definem em um estilo e existem milhares de tabelas informando isso, basta pesquisar no Google “gênero musical <insira nome do artista aqui>”. Porque pareceu uma tarefa interessante!
Objetivos
Mas como fazer isso? Vou te dizer agorinha e mais na frente irei explicar cada passo do processo mais a fundo:
1° – Vou fazer um computador vasculhar o famoso cifraclub.com.br para extrair todos os acordes de todos os artistas disponíveis em sua biblioteca;
2° – Vou analisar cada artista e criar um modelo dele usando uma cadeia de Markov de ordem a ser definida e a sequência de acordes usados pelo artista;
3° – Com o modelo de cada artista, vou analisar seus parâmetros de modo a conseguir agrupar os músicos em grupos (clusterizar);
Hipótese: Ao agrupar os artistas em clusters usando os modelos de cada músico, esses grupos irão realmente representar o estilo musical de deles? (Não sei, vamos ver no decorrer deste trabalho)
1° Passo
Desenvolver um programa vasculhador de sites (popularmente chamados de “crawlers” ou “spiders”) é uma tarefa bastante popular na internet atualmente. Por este motivo, vários vídeos, textos e documentações de linguagens de programação guiam o entusiasta neste processo. Comigo não foi diferente, o código implementado para vasculhar o site cifraclub.com.br foi uma adaptação de um passo a passo de um canal de ensino de programação chamado “The New Boston”.
Antes de descrever o código utilizado, é bom saber que o cifraclub possui uma base de dados de acordes e artistas enorme organizada em ordem alfabética (Todos os artistas de A a Z). Então caso você deseje rodar esse código para todas as letras do alfabeto, reserve um bom tempo deixando seu computador ligado. A pouco tempo meu computador passou 2 dias ligado direto rodando o código e só conseguiu terminar de baixar a letra A. Esteja avisado! O código está disponível neste link :
https://www.dropbox.com/s/eul8ytye6vpo1xm/crawler.py?dl=0 (não se assuste com a bagunça!)
O código que vasculha o cifraclub consiste em três passos importantes:
A – Listar todos os artistas de uma Letra: O código abre a página “www.cifraclub.com.br/letra/<letra que deve ser listada>/lista.html” e procura por todos os links com classe “g-1 g-fix list-links art-alf” ( que são os links de cada artista );
B – Listar todas as músicas do artista: Ao gravar todos os links dos artistas de uma letra, o código agora abre cada página do artista e lista as músicas dele. Para isso o código busca no html da página do artista os links de classe “art_music-link”.
C – Extrair os acordes da música: Este é o objetivo final do crawler. Para poder analisar a harmonia (quais acordes são executados e em qual ordem) é necessário que os acordes sejam capturados na mesma ordem que aparecem na música, felizmente a página de música do site já é organizada desta maneira. Para extrair os acordes o código busca todos os trechos do html com classe “cifra_cnt g-fix cifra-mono” ou classe “cifra_cnt g-fix cifra-arial”
Com o passo C executado, os acordes do artista são gravados em um arquivo .txt sendo cada linha (separado por um ‘\n’) correspondente a uma música. Infelizmente a base do cifraclub não é perfeita e algumas músicas não possuem acordes representado desta forma. Essas músicas são representadas como linhas sem acordes. A base extraída até o momento pode ser vista neste link :
https://www.dropbox.com/sh/bgyjfjcw9vmc3w5/AACyzoi33MQoBHw8armvg3Uka?dl=0
2° Passo
Agora que temos uma base de dados, podemos começar a analisar como os artistas arrumam os acordes em suas músicas. Como foi citado no item C do 1° Passo, a harmonia em uma música diz respeito a quais acordes são utilizados na música e em que ordem eles aparecem. Este é um problema que se encaixa perfeitamente no modelo de cadeias de Markov (Dá uma googleada que você acredita), então porque não modelar os arranjos harmônicos de cada artista como cadeias de Markov?
Uma cadeia de Markov modela o que pode acontecer num próximo instante de tempo considerando o que aconteceu em instantes anteriores. A quantidade de instantes anteriores que você considera é o que determina a ordem da cadeia de Markov. Por exemplo, se para prever o próximo passo de um bêbado você considera os três últimos passos dele, o andar desse rapaz será modelado como uma cadeia de ordem 3. (Vão na Saraiva ou Escariz e dêem uma folheada no livro “O andar do Bêbado”, é batuta)
A graça da cadeia de Markov (pelo menos para essa aplicação) não é prever o próximo passo, e sim modelar como o sistema sem se comportado durante muito tempo. Para fazer isso, iremos observar uma sequência de eventos. A Figura 1 representa um esquema de como modelar um preditor de palavras para um corretor automático. Considere a Figura 1.a, nela temos uma sequência de acontecimentos (palavras digitadas) que aconteceram em instantes seguidos. Se considerarmos que queremos modelar o preditor com uma cadeia de Markov de ordem 3, iremos considerar as três últimas palavras digitadas para sugerir uma nova palavra. O modelo no entanto, é feito pegando blocos de palavras (chamarei esses blocos daqui para frente de anagramas) do tamanho “ordem” e vendo qual a próxima palavra, como pode ser visto na Figura 1.b. Essas transições entre anagramas e novas palavras é gravada em uma tabela de transição em que as linhas representam os anagramas e as colunas representam as novas palavras, como pode ser visto na Figura 1.c. Os números na tabela representam a ocorrência da palavra quando o anagrama é escrito.
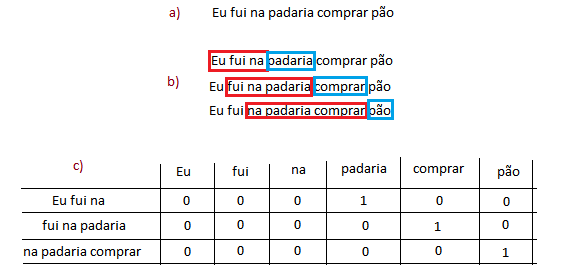
Figura 1. Ilustração de como um preditor de palavras para corretor ortográfico é modelado
Para este exemplo pequeno pode parecer inútil, mas imagine agora que a Figura 1.a fosse um texto com milhares de linhas. Poderíamos calcular a quantidade de vezes que centenas de anagramas ocorrem e quais são as palavras que sucedem eles. Fazendo com que a soma de todas as colunas em uma linha seja igual a 1 podemos dizer que os números agora representam a probabilidade de uma palavra ocorrer após certo anagrama. Esse é o poder da cadeia de Markov e é isso que é feito no código “processaArtistaMusicas.py” que está disponível aqui:
https://www.dropbox.com/s/2ozxbkudzt7pry4/processaArtistaMusicas.py?dl=0
Este código interpreta a base de dados de cada artista e organiza os acordes como se fossem cada palavra na Figura 1.a. A saída deste código é uma tabela de transição com os anagramas de acordes (linhas) e os acordes que podem suceder o anagrama (colunas). Existem outras informações interessantes que podem ser retiradas deste código também, como biblioteca de acordes de um certo artista e quantidade de músicas com acordes, mas isso não importa tanto por agora.
3° Passo
É aqui que a magia acontece. Infelizmente ainda não fiz nada por aqui, nem tenho uma idéia concreta do que fazer para clusterizar os modelos. Vamos ver no futuro.
Deixe um comentário